NHibernate
The object-relational mapper for .NET
[The motivations for releasing S#arp Lite, in relation to S#arp Architecture, are described here.]
S#arp Lite is an architectural framework for the development of well-designed, custom-built, ASP.NET MVC applications using NHibernate for data access.
![]() ASP.NET MVC 3 is a terrific platform for delivering web-based applications. But, similar to ASP.NET, it does not provide specific guidelines for how to best use it in different project contexts. That's certainly the point; it exists to provide a flexible platform which may be used in a variety of situations without being biased towards one architecture or another, beyond the fundamentals of Model-View-Controller. The benefit of this is that you can structure MVC projects almost anyway you'd like; the drawback is that it's possible to have almost no consistency among your organization's projects, even if they're all using ASP.NET MVC.
ASP.NET MVC 3 is a terrific platform for delivering web-based applications. But, similar to ASP.NET, it does not provide specific guidelines for how to best use it in different project contexts. That's certainly the point; it exists to provide a flexible platform which may be used in a variety of situations without being biased towards one architecture or another, beyond the fundamentals of Model-View-Controller. The benefit of this is that you can structure MVC projects almost anyway you'd like; the drawback is that it's possible to have almost no consistency among your organization's projects, even if they're all using ASP.NET MVC.
That's where S#arp Lite comes in to play. S#arp Lite comes packaged with three primary assets to provide a turnkey solution for developing well-designed, MVC applications:
Currently, the architectural guidance is demonstrated via the sample project which has been included in the S#arp Lite release package. Architectural guidelines are also enforced by the direction of dependencies among the project layers. (This will be discussed in more detail below.)
The overall objective is to allow your development team to more easily develop ASP.NET MVC applications which adhere to well founded principles, such as domain-driven design and test-driven development; without being bogged down with infrastructural setup and without sacrificing long-term maintainability and scalability of the solution.
As a quick side, the base repository class which S#arp Lite exposes is purposefully very simplistic. The base repository only includes the following methods:
Keeping the base repository very light has greatly reduced bloat and places greater emphasis on the use of LINQ for retrieving results from GetAll(). We'll discuss this in more detail a bit later.
The motivation for S#arp Lite came from working with many teams (including my own) who had been developing projects with S#arp Architecture. To many, S#arp Architecture is simply too big of an architectural framework to easily get your head. When I used to discuss S#arp Architecture with teams who were considering using it, I would always suggest that their developers be very experienced and well versed with topics such as dependency inversion, low-level NHibernate, and domain-driven design.
The reality of business is that it's not likely that your team will be made up of all senior level developers who are all experts in these topics. S#arp Lite is intended to epitomize the underlying values of S#arp Architecture, strive to be equally scalable to larger projects, all while being tenable to a larger audience. In other words, you should be able to have a realistically skill-balanced team and still be able to successfully deliver a S#arp Lite application.
S#arp Lite is recommended for any mid-to-large sized ASP.NET MVC project. If you have a small mom & pop store, you'd likely be better off using a less-tiered application setup. It scales well to very large projects. We're using it effectively on for applications which integrate with a half dozen other systems...so it certainly holds up to larger tasks as well.
Creating a new S#arp Lite project is trivially simple:
After you've created a S#arp Lite project, you'll find the following directory structure under the root folder:
The auto-generated folder structure is just a means to help keep your digital assets and solution files organized. The more interesting stuff is in the /app folder which houses the source code of the solution. Before we delve into the projects included in a S#arp Lite project, let's take a birds eye view of the overall architecture.
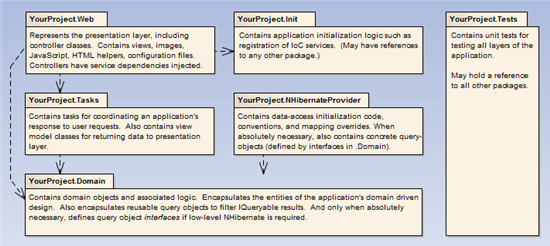
The diagram above reflects the layers of a S#arp Lite project, implemented as separate class libraries and an ASP.NET MVC Web Project. Having the tiers in separate class libraries allows you to enforce the direction of dependency among them. For example, because YourProject.Tasks depends on YourProject.Domain, YourProject.Domain cannot have any direct dependencies on a calss within YourProject.Tasks. This singled-directional dependency helps to enforce how the architecture is to remain organized.
While the diagram above describes the basic purpose of each layer, it's most assistive to look at an example project to have a clearer understanding of the scope of responsibilities of each layer. Accordingly, let's examine the tiers of the MyStore example application which was included in the S#arp Lite release package.
The MyStore sample application, included in the release zip, demonstrates the use of S#arp Lite for a fairly typical CRUD (create/read/update/delete) application. It includes managing data and relationships such as one:one, one:many, many:many, and parent/child. Let's take a closer look at the relational model.
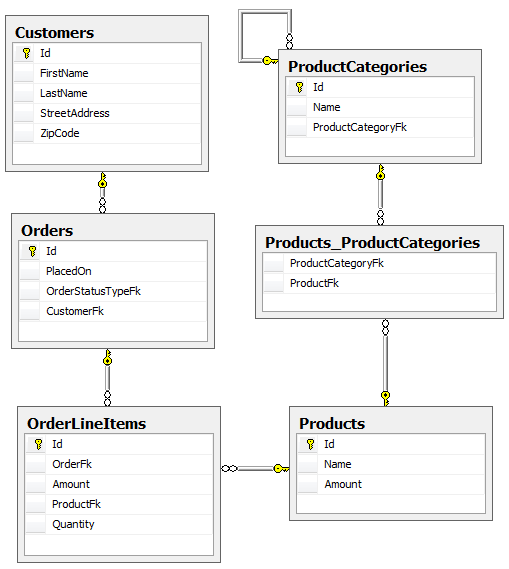
The diagram above represents the relational object model, as implemented within a SQL Server database. It's a very simple model with basic relationships, but it still brings up a lot of interesting discussion points when we go to translate this relational model into the object-oriented design of our application.
For example, each customer entity contains address information (stored as StreetAddress and ZipCode in the Customers table); in the domain, we want the address information pulled out into a separate object called Address. Having this information as a separate object more easily allows us to add behavior to the Address object while keeping those concerns separate from the Customer object, such as integration with a USPS address validation service. (Arguably, such a service would be in a stand-alone service class, but you get the idea.)
As another example, the many:many Products_ProductCategories table shouldn't have a similarly named class in our object model; instead, we would expect Products to have a listing of ProductCategories and/or vice-versa.
The sample application includes examples of how all of this and mappings of the classes themselves have been achieved almost entirely via coding-by-convention. Let's now look at the sample application, layer-by-layer, and interesting points along the way.
This layer of the application contains the heart of the application; it represents the core domain of our product. All the other layers exist simply to support the user's need to interact with the domain. In a S#arp Lite project, the domain layer contains four types of objects:
Let's review each in turn.
Domain Objects
Alright, so maybe this is a whole bunch of types of objects, but they all have the same purpose - they exist to implement the domain of our application. They consist of entities, value objects, services (e.g., calculators), factories, aggregates...all organized into modules, usually expressed as separate namespaces. (I highly recommend Eric Evans' Domain-Driven Design, Jimmy Nilsson's Applying Domain Driven Design and Patterns, and Agile Software Development by Robert Martin to help guide you.) There are two namespaces in the sample project: the "ProductMgmt" namespace which contains everything related to product management, and the "root" namespace for, well, everything else. Your project will likely have others.
Let's now take a look at the Customer class within the sample project as an example of an entity. There are some important items to note:
[HasUniqueDomainSignature(...
public class Customer : Entity
{
[DomainSignature]
...
public virtual string FirstName { get; set; }
public class Customer : Entity
{
public Customer() {
Orders = new List();
}
public virtual IList Orders { get; protected set; }
Query Objects
Regularly, we need to filter information returned from the database. For example, we may just want to return "active" customers vs. all the customers in the database. For performance reasons, it's obviously better to put as much filtering work on the shoulders of the database. Before LINQ providers, it was difficult to find the appropriate balance between filtering on the domain side or filtering on the database side. But with LINQ and IQueryable, filtering can be developed within the domain while it's still executed on the database. Brilliant! To facilitate this, every repository (e.g., IRepository<Customer>) exposes the method GetAll() which returns IQueryable<>.
The abso-friggin-spectacular side effect of this is that we can avoid having specialty "repository" methods which exist simply to hide away the details of the underlying data-access mechanism. There are two kinds of query objects in a S#arp Lite project:
public static class FindActiveCustomersExtension
{
public static IQueryable FindActiveCustomers(this IQueryable customers) {
return customers.FindActiveCustomers(MINIMUM_ORDERS_TO_BE_CONSIDERED_ACTIVE);
}
public static IQueryable FindActiveCustomers(this IQueryable customers, int minimumOrders) {
return customers.Where(c =>
c.Orders.Count >= minimumOrders);
}
private const int MINIMUM_ORDERS_TO_BE_CONSIDERED_ACTIVE = 3;
}
To me, the real beauty in this is that the query object may live in the domain, and be tested as a first class citizen of the domain, without introducing any dependencies to the underlying data-access layer (whether that be NHibernate, Entity Framework, etc.). public static class QueryForCustomerOrderSummariesExtension
{
public static IQueryable QueryForCustomerOrderSummaries(this IQueryable customers) {
return from customer in customers
select new CustomerOrderSummaryDto() {
FirstName = customer.FirstName,
LastName = customer.LastName,
OrderCount = customer.Orders.Count
};
}
}
Again, the advantage of this is that it can live within the domain layer and act as a reusable reporting query without introducing dependencies to the underlying data-access layer.
You have a lot of flexibility on how you use query objects and where they live. For example, you could use an ad-hoc report query (i.e., a LINQ query not encapsulated by a class) which lives within a method in the tasks layer. Although I'd advise against it, you could even use an ad-hoc query within a controller's method. So the provided samples are just that, samples of a particular approach. What's most important is to agree as a team how you'll encapsulate and organize query objects. In the sample project, queries are encapsulated as query objects and stored within a "Queries" folder - one folder per namespace.
Query Interfaces
In the very unlikely event that you need to leverage the data-access mechanism directly, instead of LINQing IQueryable, the domain layer may also contain any query interfaces which define a query to be implemented by the data-access layer. (This is akin to creating custom repository interfaces in S#arp Architecture.)
The disadvantages to this approach are three-fold:
But, I can foresee that there may be a situation where this is necessary if you have a very complicated query, need to leverage NHibernate detached queries, or simply can't do what needs to be done via LINQ. Accordingly, three steps would need to be taken to support the query:
Obviously, not as clean as using Specification and Report Query Objects, but available if absolutely necessary.
Custom Validators
As discussed previously, S#arp Lite uses .NET's data annotations for supporting validation. (You could use something else, like NHibernate.Validator if you prefer.) The data annotations are added directly to entity classes, but could instead be added to form DTOs if you feel that entities shouldn't act as form validation objects as well.
Sometimes, data annotations aren't powerful enough for the needs of your domain; e.g., if you want to compare two properties. Accordingly, you can develop custom validators and store them within a "Validators" folder. If the custom validator is specific to a class, and never reused, then I'll usually just add the custom validator class as a private subclass to the class which uses it. In this way, the class-specific validator is neatly tucked away, only accessible by the class which needs it. S#arp Lite uses a custom validator to determine if an object is a duplicate of an existing object, using its domain signature: \SharpLiteSrc\app\SharpLite.Domain\Validators\HasUniqueDomainSignatureAttribute.cs.
This layer of the application contains the task-coordination logic, reacting to commands sent from, e.g., a controller in the presentation layer. (This layer is also described as a Service Layer in Martin Fowler's PoEAA.) For example, let's assume that your application integrates with a number of other applications. This layer would communicate with all of the other applications (preferably via interfaces), collating the information, and handing it off to the domain layer for performing domain logic on the data. As a simpler example, if your domain layer contains some kind of FinancialCalculator class, the tasks layer would gather the information needed by the calculator, from repositories or other sources, and pass the data via a method to FinancialCalculator.
As a secondary responsibility, the tasks layer returns data, as view-models, DTOs, or entities, to the presentation layer. For example, the presentation layer may need to show a listing of customers along with Create/Edit/Delete buttons if the logged in user has sufficient rights to do so. The tasks layer would get the listing of customers to show and would determine what security access the user has; it would then return a view model containing the customers listing along with a bool (or security object) describing if the user has rights to modify the data.
It's important to note the difference between the logic found within the tasks layer and that found within the domain layer. The tasks layer should contain minimal logic to coordinate activities among services (e.g., repositories, web services, etc.) and the domain layer (e.g., calculator services). Think of the tasks layer as an effective boss (does that exist?)...the boss helps to facilitate communications among the team and tells the team members what to do, but doesn't do the job itself.
The tasks layer contains two kinds of objects:
Task Objects
These are the tasks themselves. The most common kind of task is coordinating CUD logic (CRUD without the read). It's so common, in fact, that S#arp Lite projects includes a (completely customizable) BaseEntityCudTasks class to encapsulate this common need. Looking at the sample project, you can see how BaseEntityCudTasks is extended and used; e.g., within MyStore.Tasks.ProductMgmt.ProductCudTasks.
As the project grows, the task-layer responsibilities will inevitably grow as well. For example, on a current project which integrates with multiple external applications, a task class pulls schedule information from Primavera 6, cost information from Prism, and local data from the database via a repository. It then passes all of this information to a MasterReportGenerator class which resides in the domain. Accordingly, although the task class is non-trivial, it's simply pulling data from various sources, leaving it up to the domain to the heavy processing of the data.
It's important to note that a task object's service dependencies (repositories, web services, query interfaces, etc.) should be injected via dependency injection. This facilitates the ability to unit test the task objects with stubbed/mocked services. With MVC 3, setting up dependency injection is very simple and makes defining your task objects dependencies a breeze:
public ProductCategoryCudTasks(IRepository<ProductCategory> productCategoryRepository) : base(productCategoryRepository) {
_productCategoryRepository = productCategoryRepository;
}
Here we see that the ProductCategoryCudTasks class requires a IRepository<ProductCategory> injected into it, which will be provided at runtime by the IoC container or by you when unit testing.
View Models
A view model class encapsulates information to be shown to the user. It doesn't say how the data should be displayed, only what data should be displayed. Frequently, it'll also include supporting information for the presentation layer to then decide how the information is displayed; e.g., permissions information.
There's a lot of debate about where view model classes should reside. In my projects, I keep them in the tasks layer, with one ViewModels folder per namespace. But arguably, view model classes could live in a separate class library; that's for your team to decide at the beginning of a project.
MyStore.Web
There's not much to say here. A S#arp Lite project uses all out-of-the-box MVC 3 functionality for the presentation layer, defaulting to Razor view engines, which you may change if preferred. The only S#arp Lite-isms (totally a word) in this layer are as follows:
DependencyResolverInitializer.Initialize(); to initialize the IoC container (discussed below),SharpModelBinder extends the basic form/model binding with capabilities to populate relationships. For example, suppose you have a Product class with a many:many relationship to ProductCategory. When editing the Product, the view could include a list of checkboxes for associating the product with one or more product categories. SharpModelBinder looks for such associations in the form and populates the relationships when posted to the controller; i.e., the Product which gets posted to the controller will have its ProductCategories populated, containing one ProductCategory for each checkbox that was checked. You can take a look at MyStore.Web/Areas/ProductMgmt/Views/Products/Edit.cshtml as an example.
Like task objects, controllers also accept dependencies via injection; e.g. MyStore.Web.Areas.ProductMgmt.Controllers.ProductsController.cs:
public ProductsController(IRepository<Product> productRepository,
ProductCudTasks productMgmtTasks, IQueryForProductOrderSummaries queryForProductOrderSummaries) {
_productRepository = productRepository;
_productMgmtTasks = productMgmtTasks;
_queryForProductOrderSummaries = queryForProductOrderSummaries;
}
In the example above, the controller requires an instance of IRepository<Product>, ProductCudTasks, and IQueryForProductOrderSummaries passed to its constructor from the IoC container. IQueryForProductOrderSummaries is an example of using a query interface, defined in the domain, for providing data-access layer specific needs. It's a very exceptive case and has only been included for illustrive purposes. You'd almost always be able to use specification and report query objects instead...or simply LINQ right off of IRepository<Product>.GetAll().
If you'd like to learn more about dependency injection in ASP.NET MVC 3, check out Brad Wilson's series of posts on the subject. And for learning more about the basics of developing in the web layer, Steve Sanderson's Pro ASP.NET MVC 3 Framework is a great read.
This nearly anemic layer has one responsibility: perform generic, application initialization logic. Specifically, the initialization code included with a S#arp Lite project initializes the IoC container (StructureMap) and invokes the initialization of the NHibernate session factory. Arguably, this layer is so thin that its responsibilities could easily be subsumed by MyStore.Web. The great advantage to pulling the initialization code out into a separate class library is that MyStore.Web requires far fewer dependencies. Note that MyStore has no reference to NHibernate.dll nor to StructureMap.dll. Accordingly, there is very little coupling (i.e., none) to these dependencies from the web layer...we like that. Among other things, this prevents anyone from invoking an NHibernate-specific function from a controller. This, in turn, keeps the controllers very decoupled from the underlying data-access mechanism as well.
The next stop on our tour of the layers of a S#arp Lite project is the NHibernate provider layer. With S#arp Architecture, this layer would frequently get quite sizable with custom repositories and named queries. With the alternative use of query objects and LINQ on IQueryable<>, this class library should remain very thin. This class library contains three kinds of objects:
Let's look at each in turn.
NHibernate Initializer
NHibernate 3.2.0 introduces a built-in fluent API for configuration and mapping classes, nicknamed NHibernate's "Loquacious" API. This is a direct affront to Fluent NHibernator which (as much as I have truly loved it...a sincere thank you to James Gregory) I feel is headed for obsolescence with these capabilities now being built right in to NHibernate. NHibernate 3.2's Loquacious API isn't yet as powerful as Fluent NHibernate, but will get there soon as more of ConfORM is ported over to Loquacious API. On with the show...
There is one NHibernate initialization class with a S#arp Lite project; e.g., MyStore.NHibernateProvider.NHibernateInitializer.cs. This class sets the connection string (from web.config), sets the dialect, tells NHibernate where to find mapped classes, and invokes convention setup (discussed next). Initializing NHibernate is very expensive and should only be performed once when the application starts. Accordingly, take heed of this if you decide to switch out the IoC initialization code (in MyStore.Init) with another IoC container.
NHibernate Conventions
The beauty of conventions is that we no longer need to include a class mapping (HBM or otherwise) for mapping classes to the database. We simply define conventions, adhere to those conventions, and NHibernate knows which table/columns to go to for what. S#arp Lite projects come prepackaged with the following, customizable conventions:
There is typically just one convention-setup class in a S#arp Lite project; e.g., MyStore.NHibernateProvider.Conventions. The only convention that isn't supported "out of the box" is a many:many relationship, which we'll discuss more below.
Mapping Overrides
There are times when conventions don't hold up. Examples include:
On the upside, this isn't too many cases...but we need to be able to handle the exceptions. Any exceptions to the conventions are defined as "mapping overrides." Examples of overrides may be found in MyStore.NHibernateProvider/Overrides. To make things easy, if an override needs to be added, simply implement MyStore.NHibernateProvider.Overrides.IOverride and include your override code. The MyStore.NHibernateProvider.Conventions class looks through the assembly for any classes which implements IOverride and applies them in turn. As a rule, I create one override class for each respective entity which requires an override.
Query Implementations
Lastly, the .NHibernateProvider layer contains any NHibernate-specific queries, which are implementations of respective query interfaces defined in the .Domain layer. 97.6831% of the time, this will not be necessary as querying via LINQ, off of IQueryable<>, is the preferred approach to querying. But in the rare case that you need to implement a query using NHibernate Criteria, HQL, or otherwise, this is the layer to house it. A sample has been included as MyStore.NHibernateProvider.Queries.QueryForProductOrderSummaries.
At the end of our tour of the layers of a S#arp Lite project is the .Tests layer. This layer holds all of the unit tests for the project. S#arp Lite projects are generated with two unit tests out of the box:
For an introduction to test-driven development, read Kent Beck's Test Driven Development: By Example. Going a step further, go with Gerard Meszaros' xUnit Test Patterns and Michael Feathers' Working Effectively with Legacy Code.
In S#arp Architecture, SQLLite was used to provide an in-memory database for testing custom repository methods. Since custom repositories have been mostly relegated to obsolescence, keeping SQLLite testing built-in to S#arp Lite would have been overkill and has been removed to keep things simpler. (Besides, you can always look at the S#arp Architecture code for that functionality if needed.)
Most of what's relevant in the S#arp Lite class libraries has already been discussed while going through the sample project, but let's take a moment to see what all is in the reusalbe, S#arp Lite class libraries.
This class library provides support for the domain layer of your S#arp Lite project.
The idea of this library is to provide a pluggable replacement for the NHibernateProvider (discussed next), if the team so chooses. This library has not been fully developed yet. Let me know if you're interested in contributing with this effort.
This infrastructural class library provides everything necessary for S#arp Lite projects to communicate with the database via NHibernate.
This class library provides MVC-specific needs for S#arp Lite projects...which consists entirely of SharpModelBinder.cs. This may be viewed as completely optional for your use in S#arp Lite projects.
Well, that's it in a nutshell for now. I sincerely hope that S#arp Lite will prove helpful to you and your team in developing well-designed, maintainable ASP.NET MVC applications that scale well as the project evolves. This architectural framework reflects lessons learned from years of experience blood, sweat, & tears and countless ideas shamelessly stolen from those much smarter than I.
Enjoy!
Billy McCafferty
http://devlicio.us/blogs/billy_mccafferty